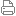
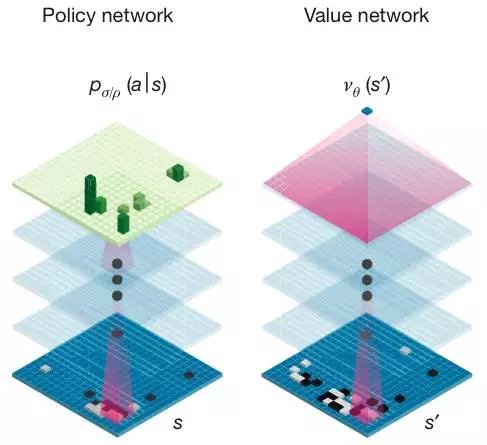
随着顶级科技公司争相在产品中融入智能技术,谷歌并不是唯一一家研究围棋AI的公司,Facebook对围棋人工智能的研究整合此前也亮相最新的计算技术:深卷积神经网络(deep convolutional neural networks)和蒙特卡洛树搜索(Monte Carlo tree search),前者利用类似于大脑的算法来学习和识别棋盘上各种模式的重要性,而后者相当于一种超前思维,用于计算详细的战略步骤。
谷歌DeepMind团队自称“人工智能领域的阿波罗计划”。2015年10月,他们在伦敦组织了一场机器与人类之间的对决。该团队研发的系统名叫AlphaGo,它要对付的人类选手是欧洲围棋冠军樊麾。在《自然》杂志的一名编辑和英国围棋联合会(British Go Federation)的一名权威人士的监督下,他们连续进行了五轮较量,AlphaGo均取得了胜利。“无论是作为一名研究人员还是编辑,这都算是我职业生涯中最令人激动的时刻之一。”《自然》杂志编辑唐吉?肖尔德博士(Tanguy Chouard)在本周二的一次记者会上说道。





 发表于 2016-1-28 23:49:32
发表于 2016-1-28 23:49:32







 收藏
收藏 分享
分享