|
还记得经典科幻电影《2001 太空漫游》中的飞船主控计算机 Hall 吗?它具有依靠阅读说话人的嘴唇运动理解其所表达的内容的能力,这种能力也在推动那个幻想故事的情节发展中起到了至关重要的作用。近日,牛津大学、Google DeepMind 和加拿大高等研究院(CIFAR)联合发布了一篇同样具有重要价值的论文,介绍了利用机器学习实现的句子层面的自动唇读技术 LipNet。该技术将自动唇读技术的前沿水平推进到了前所未有的高度。原论文可点击文末「阅读原文」下载。 
摘要
唇读(lipreading)是指根据说话人的嘴唇运动解码出文本的任务。传统的方法是将该问题分成两步解决:设计或学习视觉特征、以及预测。最近的深度唇读方法是可以端到端训练的(Wand et al., 2016; Chung & Zisserman, 2016a)。但是,所有已经存在的方法都只能执行单个词的分类,而不是句子层面的序列预测。研究已经表明,人类在更长的话语上的唇读表现会更好(Easton & Basala, 1982),这说明了在不明确的通信信道中获取时间背景的特征的重要性。受到这一观察的激励,我们提出了 LipNet——一种可以将可变长度的视频序列映射成文本的模型,其使用了时空卷积、一个 LSTM 循环网络和联结主义的时间分类损失(connectionist temporal classification loss),该模型完全是以端到端的形式训练的。我们充分利用我们的知识,LipNet 是第一个句子层面的唇读模型,其使用了一个单端到端的独立于说话人的深度模型来同时地学习时空视觉特征(spatiotemporal visual features)和一个序列模型。在 GRID 语料库上,LipNet 实现了 93.4% 的准确度,超过了经验丰富的人类唇读者和之前的 79.6% 的最佳准确度。 1 引言
唇读在人类的交流和语音理解中发挥了很关键的作用,这被称为「麦格克效应(McGurk effect)」(McGurk & MacDonald, 1976),说的是当一个音素在一个人的说话视频中的配音是某个人说的另一个不同的音素时,听话人会感知到第三个不同的音素。 唇读对人类来说是一项众所周知的艰难任务。除了嘴唇和有时候的舌头和牙齿,大多数唇读信号都是隐晦的,难以在没有语境的情况下分辨(Fisher, 1968; Woodward & Barber, 1960)。比如说,Fisher (1968) 为 23 个初始辅音音素的列表给出了 5 类视觉音素(visual phoneme,被称为 viseme),它们常常会在人们观察说话人的嘴唇时被混淆在一起。许多这些混淆都是非对称的,人们所观察到的最终辅音音素是相似的。 所以说,人类的唇读表现是很差的。听觉受损的人在有 30 个单音节词的有限子集上的准确度仅有 17±12%,在 30 个复合词上也只有 21±11%(Easton & Basala, 1982)。 因此,实现唇读的自动化是一个很重要的目标。机器读唇器(machine lipreaders)有很大的实用潜力,比如可以应用于改进助听器、公共空间的静音听写、秘密对话、嘈杂环境中的语音识别、生物特征识别和默片电影处理。机器唇读是很困难的,因为需要从视频中提取时空特征(因为位置(position)和运动(motion)都很重要)。最近的深度学习方法试图通过端到端的方式提取这些特征。但是,所有的已有工作都只是执行单个词的分类,而非句子层面的序列预测(sentence-level sequence prediction)。 在这篇论文中,我们提出了 LipNet。就我们所知,这是第一个句子层面的唇读模型。就像现代的基于深度学习的自动语音识别(ASR)一样,LipNet 是以端到端的方式训练的,从而可以做出独立于说话人的句子层面的预测。我们的模型在字符层面上运行,使用了时空卷积神经网络(STCNN)、LSTM 和联结主义时间分类损失(CTC)。 我们在仅有的一个公开的句子层面的数据集 GRID 语料库(Cooke et al., 2006)上的实验结果表明 LipNet 能达到 93.4% 的句子层面的词准确度。与此对应的,之前在这个任务上的独立于说话人的词分类版本的最佳结果是 79.6%(Wand et al., 2016)。 我们还将 LipNet 的表现和听觉受损的会读唇的人的表现进行了比较。平均来看,他们可以达到 52.3% 的准确度,LipNet 在相同句子上的表现是这个成绩的 1.78 倍。 最后,通过应用显著性可视化技术(saliency visualisation techniques (Zeiler & Fergus, 2014; Simonyan et al., 2013)),我们解读了 LipNet 的学习行为,发现该模型会关注视频中在语音上重要的区域。此外,通过在音素层面上计算视觉音素(viseme)内和视觉音素间的混淆矩阵(confusion matrix),我们发现 LipNet 少量错误中的几乎所有都发生在视觉音素中,因为语境有时候不足以用于消除歧义。 2 相关工作
本节介绍了其它在自动唇读研究上的工作,包含了自动唇读、使用深度学习进行分类、语音识别中的序列预测、唇读数据集四个方面。但由于篇幅限制,机器之心未对此节进行编译,详情请查看原论文。 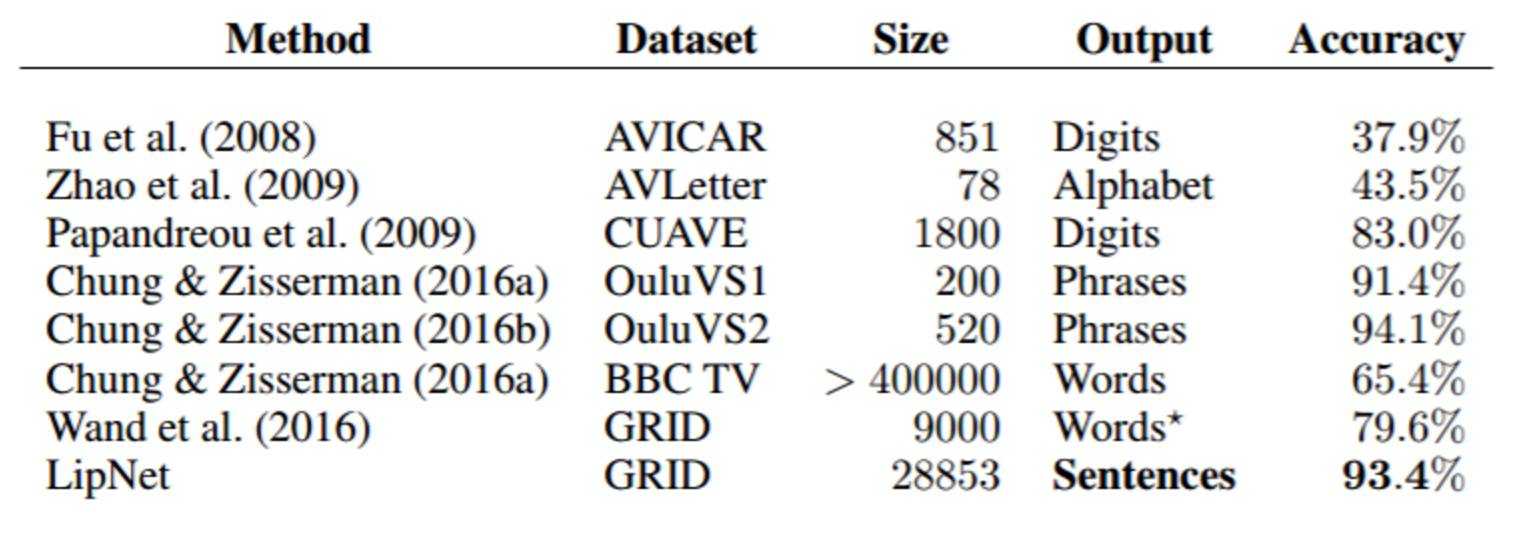
表 1:现有的唇读数据集和对应数据集上已被报告出来的最佳准确度。Size 这一栏是指作者训练时所用的话语的数量。尽管 GRID 语料库包含了整个句子,但 Wand et al. (2016) 只考虑了更简单的预测单独的词的情况。LipNet 预测的是句子,因此可以利用时间语境来实现更高的准确度。短语层面的方法被当作简单的分类看待。 3 LipNet
LipNet 是一种用于唇读的神经网络架构,其可以将不同长度的视频帧序列映射成文本序列,而且可以通过端到端的形式训练。在本节中,我们将描述 LipNet 的构建模块和架构。 3.1 时空卷积 卷积神经网络(CNN)包含了可在一张图像进行空间运算的堆叠的卷积(stacked convolutions),其可用于提升以图像为输入的目标识别等计算机视觉任务的表现(Krizhevsky et al., 2012)。一个从 C 信道到 C' 信道的基本 2D 卷积层(没有偏置(bias),以单位步长)的计算: 
对于输入 x 和权重: 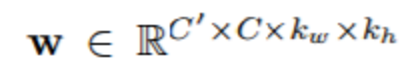
其中我们定义当 i,j 在范围之外时,xcij=0. 时空卷积神经网络(STCNN)可以通过在时间和空间维度上进行卷积运算来处理视频数据: 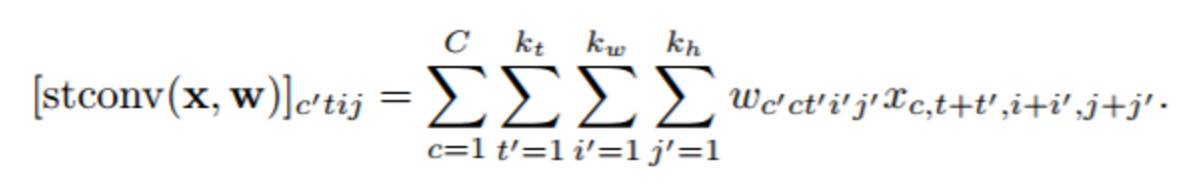
3.2 长短期记忆 长短期记忆(LSTM)(Hochreiter & Schmidhuber, 1997)是一类在早期的循环神经网络(RNN)上改进的 RNN,其加入了单元(cell)和门(gate)以在更多的时间步骤上传播信息和学习控制这些信息流。我们使用了带有遗忘门(forget gates)的标准 LSTM 形式: 
其中 z := {z1, . . . , zT } 是 LSTM 的输入序列,是指元素之间的乘法(element-wise multiplication), sigm(r) = 1/(1 + exp(?r))。 我们使用了 Graves & Schmidhuber (2005) 介绍的双向 LSTM(Bi-LSTM):一个 LSTM 映射 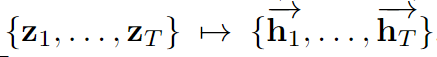
,另一个是 ,然后 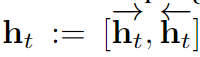
,该 Bi-LSTM 可确保 ht 在所有的 t' 上都依赖于 zt'。为了参数化一个在序列上的分布,在时间步骤 t,让 p(ut|z) = softmax(mlp(ht;Wmlp)),其中 mlp 是一个权重为 Wmlp 的前向网络。然后我们可以将长度 T 的序列上的分布定义为
,其中 T 由该 LSTM 的输入 z 确定。在 LipNet 中,z 是该 STCNN 的输出。 3.3 联结主义的时间分类 联结主义的时间分类损失(onnectionist temporal classification (CTC) loss)(Graves et al., 2006)已经在现代的语音识别领域得到了广泛的应用,因为这让我们不再需要将训练数据中的输入和目标输出对齐(Amodei et al., 2015; Graves & Jaitly, 2014; Maas et al., 2015)。给定一个在 token 类(词汇)上输出一个离散分布序列的模型——该 token 类使用了一个特殊的「空白(blank)」token 进行增强,CTC 通过在所有定义为等价一个序列的序列上进行边缘化而计算该序列的概率。这可以移除对对齐(alignment)的需求,还同时能解决可变长度的序列。用 V 表示该模型在其输出(词汇)的单个时间步骤上进行分类的 token 集,而空白增强过的词汇 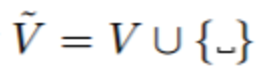
其中空格符号表示 CTC 的空白。定义函数 B : V? ? → V ?,给定 V? 上的一个字符串,删除相邻的重复字符并移除空白 token。对于一个标签序列 y ∈ V ?,CTC 定义 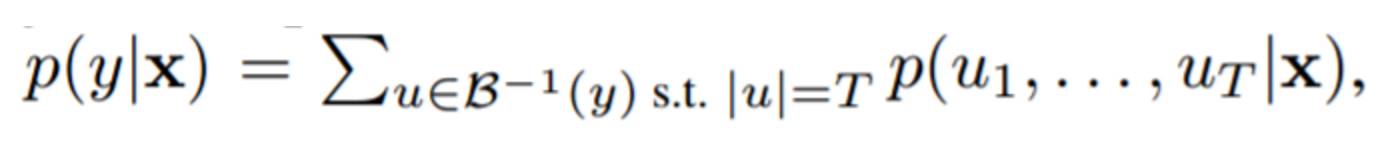
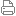
其中 T 是该序列模型中时间步骤的数量。比如,如果 T=3,CTC 定义字符串「am」的概率为
这个和可以通过动态编程(dynamic programming)有效地计算出来,让我们可以执行最大似然(maximum likelihood) 
图 1:LipNet 架构。一个 T 帧的序列被用作输入,被一个 3 层的 STCNN 处理,其中每一层后面都有一个空间池化层(spatial max-pooling layer)。提取出的特征是时间上上采样(up-sample)的,并会被一个 Bi-LSTM 处理;LSTM 输出的每一个时间步骤会由一个 2 层前向网络和一个 softmax 处理。这个端到端的模型是用 CTC 训练的。
3.4 LipNet 架构 图 1 给出了 LipNet 的架构,其始于 3×(时空卷积、信道上的 dropout、空间最大池化),后面跟随时间维度中的上采样。 因为人类每秒钟大约能发出 7 个音素,而且因为 LipNet 是在字符层面上工作的,所以我们总结得到:每秒输出 25 个 token(视频的平均帧率)对 CTC 来说太受限了。时间上采样(temporal up-sampling)允许在字符输出之间有更多的空格。当许多词有完全相同的连续字符时,这个问题会加剧,因为他们之间需要一个 CTC 空白。 随后,该时间上采样后面跟随一个 Bi-LSTM。该 Bi-LSTM 对 STCNN 输出的有效进一步会聚是至关重要的。最后在每一个时间步骤上应用一个前向网络,后面跟随一个使用了 CTC 空白和 CTC 损失在词汇上增强了的 softmax。所有的层都是用了修正线性单元(ReLU)激活函数。超参数等更多细节可参阅附录 A 的表 3. 4 唇读评估
在这一节,我们将在 GRID 上评估 LipNet。 4.1 数据增强 预处理(Preprocessing):GRID 语料库包含 34 个主题,每一个主题包含了 1000 个句子。说话人 21 的视频缺失,其它还有一些有所损坏或空白,最后剩下了 32839 个可用视频。我们使用了两个男性说话人(1 和 2)与两个女性说话人(20 和 22)进行评估(3986 个视频),剩下的都用于训练(28853 个视频)。所有的视频都长 3 秒,帧率为 25 fps. 这些视频使用 DLib 面部检测器和带有 68 个 landmark 的 iBug 面部形状预测器进行了处理。使用这些 landmark,我们应用了一个放射变换(affine transformation)来提取每帧中以嘴为中心的 100×50 像素大小的区域。我们将整个训练集上对 RGB 信道进行了标准化以具备零均值和单位方差。 增强(Augmentation):我们使用简单的变换来增强数据集以减少过拟合,得到了多 15.6 倍的训练数据。首先,我们在正常的和水平镜像的图像序列上进行训练。然后,因为该数据集提供了每个句子视频中的词开始和结束时间,所以我们使用单独的词的视频片段作为额外的训练实例增强了句子层面的训练数据。 4.2 基线 为了评估 LipNet,我们将其表现和三位懂得读唇的听觉受损者以及两个由最近的最佳成果启发的 ablation model(Chung & Zisserman, 2016a; Wand et al., 2016)的表现进行了比较。 听觉受损者:这个基线是由牛津学生残疾人社区(Oxford Students』 Disability Community)的三位成员得到的。在被介绍了 GRID 语料库的语法之后,他们从训练数据集中观察了 10 分钟带有注释的视频,然后再从评估数据集中注释了 300 个随机视频。当不确定时,他们可以选择觉得最有可能的答案。 Baseline-LSTM:使用句子层面的 LipNet 配置,我们复制了之前 GRID 语料库当时(Wand et al., 2016)的模型架构。参看附录 A 了解更多实现细节。 Baseline-2D:基于 LipNet 架构,我们使用仅空间的卷积替代了 STCNN,这类似于 Chung & Zisserman (2016a) 的那些。值得一提的是,和我们用 LipNet 观察到的结果相反,Chung & Zisserman (2016a) 报告他们的 STCNN 在他们的两个数据集上比他们的 2D 架构的性能差分别 14% 和 31%。 4.3 性能评估 
表 2:LipNet 相比于基线的性能
表 2 总结了相比于基线的性能。根据文献,人类唇读者的准确率大约是 20%(Easton & Basala, 1982; Hilder et al., 2009)。如预料的一样,GRID 语料库中固定的句子结构和每个位置有限的词子集有助于对语境的使用,能提升表现。这三位听觉受损者的词错率(WER)分别为 57.3%、50.4% 和 35.5%,平均词错率为 47.7%。 4.4 学到的表征 在这一节中,我们从语音学的角度分析了 LipNet 的学习到的表征。首先,我们创造了显著性可视化(saliency visualisations (Simonyan et al., 2013; Zeiler & Fergus, 2014))来说明 LipNet 所学的重点区域。特别地,我们向该模型送入了一个输入,并贪婪地解码了一个输出序列,得出了一个 CTC 对齐 
(遵循 3.2 和 3.3 节的符号)。然后,我们计算了 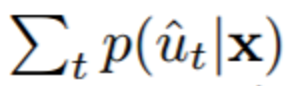
的梯度,并考虑了输入视频帧序列,但和 Simonyan et al. (2013) 不一样,我们使用了有引导的反向传播(guided backpropagation (Springenberg et al., 2014))。第二,我们训练 LipNet 预测的是 ARPAbet 音素,而不是字符,这样可以使用视觉音素(viseme)内和视觉音素间的混淆矩阵(confusion matrix)来分析视觉音素。 4.4.1 显著性地图(Saliency Maps) 我们应用显著性可视化技术(saliency visualisation techniques)来解读 LipNet 学习到的行为,结果表明该模型会重点关注视频中在语音方面重要的区域。特别地,在图 2 中,我们基于 Ashby (2013) 为说话人 25 的词 please 和 lay 分析了两个显著性可视化。 图 2:词 (a) please 和 (b) lay 的显著性地图,由向输入的反向传播产生,展示了 LipNet 学会关注的地方。图中的转录由贪婪 CTC 解码(greedy CTC decoding)给出。CTC 空白由空格符号表示。
4.4.2 视觉音素(viseme) 根据 DeLand(1931)和 Fisher(1968),Alexander Graham Bell 首次假设给定说话人的多音素可被视觉地识别。这在后来得到了证实,这也带来了视觉音素的概念,即一个音素的视觉对应(Woodward & Barber, 1960; Fisher, 1968)。为了我们的分析,我们使用了 Neti et al. (2000) 中音素到视觉音素的映射,将视觉音素聚类成了以下类别:Lip-rounding based vowels (V)、Alveolar-semivowels (A),、Alveolar-fricatives (B)、Alveolar (C)、Palato-alveolar (D)、Bilabial (E), Dental (F)、Labio-dental (G) 和 Velar (H)。完整映射可参看附录 A 中的表 4. GRID 包含了 ARPAbet 的 39 个音素中的 31 个。我们计算了音素之间的混淆矩阵(confusion matrix),然后按照 Neti et al. (2000) 将音素分组成了视觉音素聚类。图 3 表示了 3 个最容易混淆的视觉音素类别,以及视觉音素类别之间的混淆。完整的音素混淆矩阵参看附录 B 图 4. 图 3:视觉音素内和视觉音素间的混淆矩阵,描绘了 3 个最容易混淆的类别,以及视觉音素聚类之间的混淆。颜色进行了行规范化(row-normalised)以强调误差。
5. 结论
我们提出了 LipNet,它是第一个将深度学习应用于模型的端到端学习的模型,可以将说话者的嘴唇的图像帧序列映射到整个句子上。这个端到端的模型在预测句子前不再需要将视频拆分成词。LipNet 需要的既不是人工编入的时空视觉特征,也不是一个单独训练的序列模型。 我们的实证评估表明了 时空特征提取和高效的时间聚集(temporal aggregation)的重要性,确认了 Easton 和 Basala 在 1982 年提出的假说(1982)。此外,LipNet 大大超越了人类的读唇水平的基线,比人类水平高出 7.2 倍,WER 达到了 6.6%,比现在 GRID 数据集中最好的词水平(Wand 等人,2016)还要低 3 倍。 虽然 LipNet 在实证上取得了成功,Amodei 等人在 2015 年发表的深度语音识别论文显示,只有更多的数据才能让表现提升。在未来的研究中,我们希望通过将 LipNet 应用到更大的数据集中来证明这一点,如由 Chung 和 Zisserman 等人在 2016 年收集的这种数据集的句子水平变体(sentence-level variant)。像默写这样的应用只能使用视频数据。然而,为了扩展 LipNet 的潜在应用,我们能将这种方法应用到一种联合训练的视听语音识别模型上,其中视觉输入会在嘈杂的环境中提升鲁棒性。
| 





 发表于 2016-11-7 03:31:30
发表于 2016-11-7 03:31:30


 收藏
收藏 分享
分享